
Аналітична платформа ProAct
Дизайн та розробка з нуля
На початку проекту команді було надано мінімум інформації: презентація, ексель-таблиці з описом того, як повинні бути розраховані показники та попередня структура наборів даних.
В результаті наша команда з 6 фахівців разом з аналітиками Government Transparency Institute та консультантами Всесвітнього Банку розробила платформу ProAct, яка містить аналітичні інструменти, що надають доступ до відкритих даних національних електронних систем закупівель 46 країн та відкритих даних проектів, фінансованих Всесвітнім Банком та Міжамериканським банком розвитку, для понад 100 країн.
Наш клієнт
Прототип був розроблений для Всесвітнього Банку спільно з Інститутом прозорості уряду та Центром вивчення корупції при Університеті Сассексу. Методологія платформи частково базується на методології, розробленій для проекту www.opentender.eu та програми Global Integrity Anticorruption Evidence (GI-ACE), фінансованої Великою Британією через FCDO. Платформа ProACT використовує дані, зібрані в рамках цих проектів.
Наш підхід
Команда MK у тісній співпраці з зацікавленими сторонами допомогла клієнту розробити прототип, перетворюючи бачення клієнта в користувацькі історії та пропонуючи по ходу проекту технічні підходи та рішення для реалізації задач.
Посилання
Характеристики
6
фахівців у команді проекту MK
46
датасетів про закупівлі країн
2
датасети про закупівлі проектів, фінансованих Всесвітнім банком та Міжамериканським банком розвитку, по всьому світу
120
країн у датасетах
60
діапазон даних
21
контрактів
5
постачальників
1
замовників у 120 країнах
Технології

ProAct - Прототип глобальної платформи з протидії корупції та забезпечення прозорості у закупівлях
Замовник
Всесвітній Банк
Співвиконавці
Інститут прозорості уряду, Угорщина
Період надання послуг
Прототип: січень 2020 – червень 2021
Модифікації: травень 2022 – липень 2022
Мета
- Забезпечити легкий доступ до глобальних відкритих даних про публічні закупівлі з 48 датасетів.
- Дозволити користувачам виявляти, аналізувати та моніторити результи публічних закупівель та пов’язані з ними ризики, для покращення запобіжних заходів, вдосконалення процесів та реформування політик в закупівлях.
- Допомогти запобігти корупції та сприяти прозорості та чесності у публічних витратах на товари, роботи та послуги.
Результати
- оптимальні рішення, що відповідають бюджету та термінам замовника;
- зменшення витрат на обслуговування в AWS, автоматизація завантаження датасетів;
- швидкість роботи, кастомізація та масштабованість системи.
Послуги
- розробка архітектури
- розробка інфраструктури на AWS
- розробка фронт- та бекенд-коду
- оптимізація та підтримка DevOps
Складові проекту
- Веб-серверна віртуальна машина, на якій працюють сервери фронтенду та бекенду.
- ELS – Elasticsearch з обробленими даними (індексує замовників, постачальників тощо).
- Кластер EMR за запитом, для обробки наборів даних з результатами, збереженими в ELS.
- S3: обʼєктне сховище кластера EMR – використовується для зберігання коду обробки EMR (код Scala для Spark); корзина датасетів – використовується для зберігання необроблених датасетів.
- Функція Lambda, яка запускає EMR, коли новий набір даних завантажується в S3.
Завантаження наборів даних
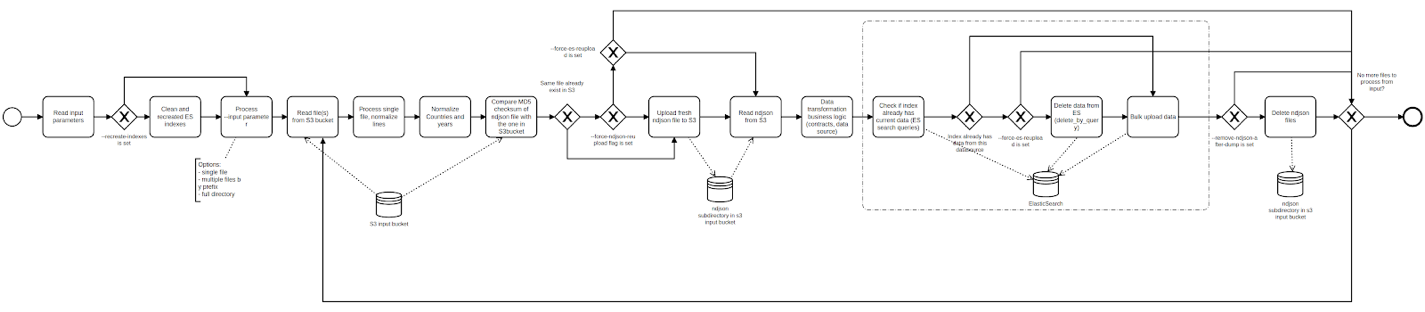
CI/CD-пайплайн організований таким чином, що при завантаженні нового набору даних або кількох наборів даних в кореневу папку S3, запускається скрипт, і набори даних починають оброблятися/розраховуватися. Під час цього процесу виконуються наступні дії, з підтвердженням в каналі Slack для кожної дії:
- Перевірка структури файлу для підтвердження, що це набір даних.
- Читання, перетворення та нормалізація вхідних даних.
- Перевірка, чи працює Elasticsearch.
- Повідомлення, якщо кластер не готовий масштабуватися.
- Перевірка, чи готовий Elasticsearch масштабуватися.
- Запуск імпорту за допомогою CI/CD-пайплайну.
- Запуск масштабування Elasticsearch.
- Повідомлення про завершення імпорту набору даних.
- Повідомлення про зупинку Elasticsearch.
- У разі завантаження кількох наборів даних разом вони ставляться в чергу на обробку.
- У разі черги або великого розміру набору даних Elasticsearch створює кілька кластерів EMR. У цьому випадку користувач отримує повідомлення в Slack.
- Завантаження нового набору даних для країни, яка вже має старий набір даних у системі, не вимагає видалення старого набору даних, а лише завантаження нового.
- Під час обробки скрипт імпорту розраховує значення та порівнює нові дані з даними у системі. Якщо він знаходить різниці, вони оновлюються, використовуючи значення з нового набору даних.
Кластер EMR
Репозиторій з кодом Scala для кластера EMR. У репозиторії є файл .gitlab-ci.yml, який відповідає за збірки та завантаження коду Scala до буфера кластера EMR.
Репозиторій з кодом Terraform, який використовується для створення кластера EMR за потребою для обробки, разом з масштабуванням ELS (для своєчасного імпорту великих обсягів даних з EMR) та зменшенням його після завершення обробки. Функція Lambda запускає імпорт EMR, коли набір даних завантажується до буфера.
Оновлення коду Lambda запускає розгортання коду в AWS.
Загальний опис робочого процесу
БІЛЬШЕ КЕЙСІВ
Filter
AllCloud computingData servicesDevelopmentE-governmentE-healthE-procurementEnterpriseInfrastructureIT consultingIT консалтингLLM AILLM AIMachine learning and AINetwork securitySoftwareSupportTestБезпека мережЕлектронна комерціяЕлектронне Здоров'яЕлектронний урядЕлектронні закупівліЕнтерпрайсІнфраструктураМашинне навчання та ШІПрограмне забезпеченняРобота з данимиРозробкаХмарні обчислення




